
.png)
.png)
ENG


Knihovní data jsou rozsáhlá, živá a neustále se mění. Migrují, doplňují se, opravují. Vznikají často desítky let a nesou v sobě historické vrstvy starších pravidel, retrokonverzí i ručních zásahů. A když se člověk začne katalogem nebo digitální knihovnou některé z institucí systematicky probírat, rychle zjistí, že jedna oprava odkrývá další problémy.
.png)
Na konferenci AKM 2025 jsme tento jev přirovnali k boji s hydrou – useknete jednu hlavu a narostou další tři.
To se ale netýká jen knihoven. Podobnou zkušenost má každá organizace, která pracuje s velkým množstvím dat. Jakmile data rostou a vyvíjejí se v čase, začnou se v nich přirozeně objevovat nekonzistence, duplicity nebo nejednotné zápisy.
Odborník přitom mnohdy ví, že v datech něco není v pořádku. Vidí jednotlivé chyby, ale nemá nástroj, který by mu umožnil jednoduše zjistit jejich rozsah ani souvislosti ve větším měřítku.ale nedokáže
A proto vznikl Anakon.

Řada činností při práci s daty vypadá na první pohled jednoduše. Potřebuji připravit podklady, zkontrolovat konzistenci dat, ověřit vazby mezi systémy nebo vytvořit přehled pro další rozhodování.
V praxi se ale tyto úkoly často rozpadnou na desítky drobných kroků:
Taková práce je časově náročná a obtížně škálovatelná. Čím větší objem dat, tím méně je reálné ji dělat ručně. A zároveň tím víc roste tlak na přesnost.
Výsledkem je paradox: lidé s hlubokou znalostí dat tráví velkou část času mechanickou činností místo toho, aby data skutečně analyzovali. A protože se data průběžně mění, výsledek takové práce rychle zastarává a je potřeba ho opakovat.
V mnoha institucích řeší analýzu dat přes požadavky na IT oddělení. Knihovník potřebuje data, technik připraví dotaz a export. Tento model na papíře funguje, ale v praxi má své limity.
Knihovník formuluje požadavek, IT ho implementuje a po čase vrátí výsledek. Jenže se ukáže, že zadání bylo potřeba upřesnit. Následuje další iterace. Mezitím se data změní nebo se objeví nové otázky.
Proces se opakuje.

Další bariérou je i komunikační jazyk: každý pracuje s daty jiným způsobem a jinak o nich přemýšlí. Knihovník řeší obsah a struktury záznamu, technický pracovník zase databáze a indexy. Výsledek se pak ladí postupně, někdy i několik iterací.
Tenhle nekonečný cyklus není nijak neobvyklý nebo výjimečný ani mimo knihovnické prostředí. Vzniká všude, kde jsou analytické potřeby oddělené od nástrojů, které s daty pracují, a vede k dlouhodobé frustraci na obou stranách.
Kořeny Anakonu sahají do roku 2012. Honza Rychtář (dnes CEO Trinera) tehdy jako programátor v Moravské zemské knihovně neustále řešil požadavky na výpisy a kontroly dat, které katalog nedokázal nabídnout. Místo opakovaného psaní skriptů tak vytvořil MarcScanner – interní nástroj, který knihovníkům umožnil pokročilou práci s daty bez asistence IT oddělení.

Nebyl to produkt ani systémová změna. Spíš praktická reakce na konkrétní potřebu.
Později se ukázalo, že stejný princip má širší využití – zejména ve chvíli, kdy je potřeba pracovat nejen s katalogem, ale i s digitální knihovnou a jejich vzájemnými vazbami. V rámci projektu Národního plánu obnovy tak vznikl pro potřeby Moravské zemské knihovny Anakon.
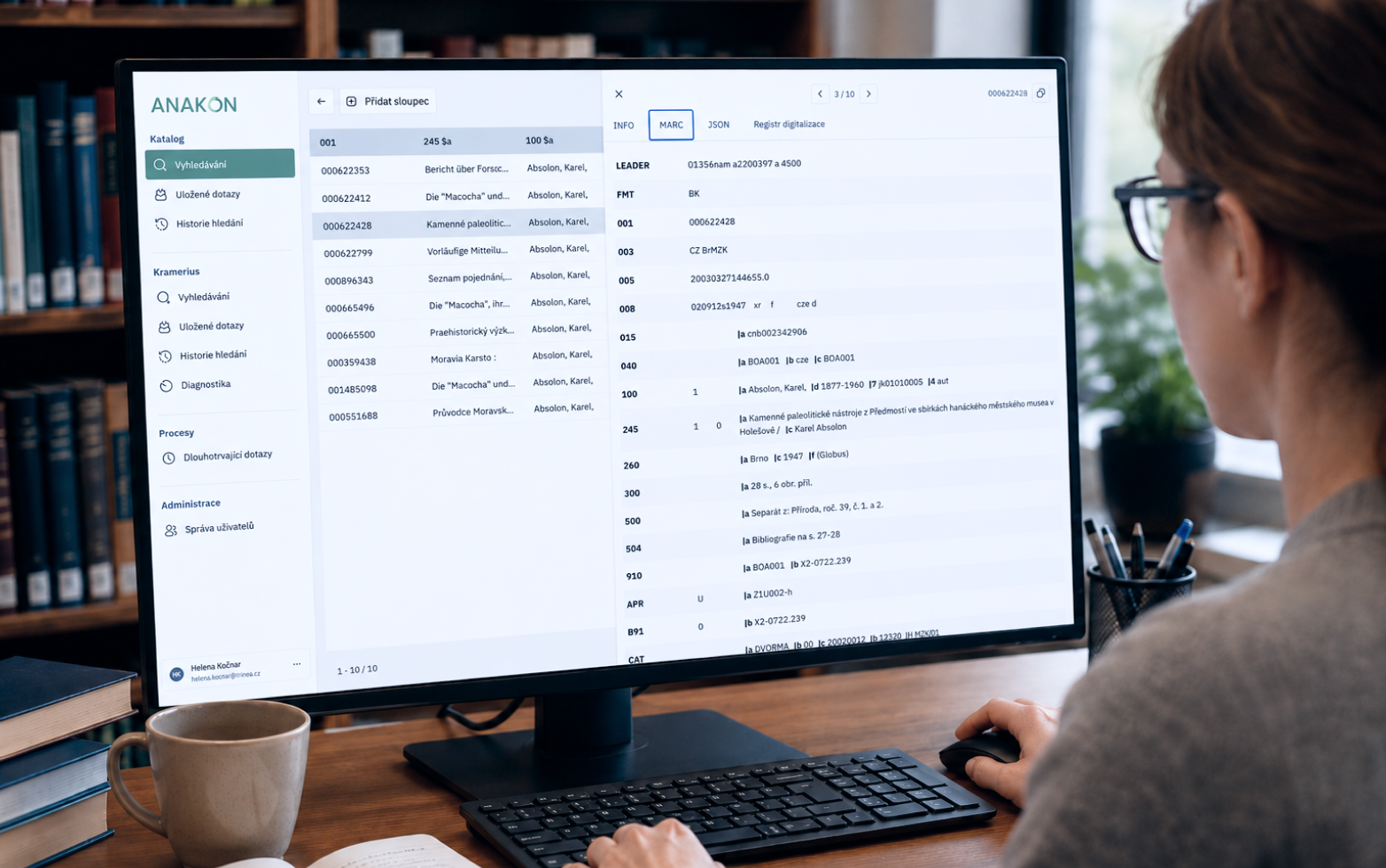
Anakon je analytický a kontrolní nástroj, který doplňuje existující systémy. Nenahrazuje katalog ani digitální knihovnu a neslouží k přímé úpravě dat. Zato ale nad daty umožňuje pokládat otázky, na které běžná rozhraní nestačí.
Uživatel si vybere zdroj dat, nastaví podmínky a získá výsledek ve formě přehledné tabulky. Každý řádek odpovídá jednomu záznamu, jednotlivé sloupce představují vybrané údaje nebo kontrolní hodnoty.
Tento způsob práce je důležitý. Nejde jen o to data najít, ale vidět je v souvislostech – řadit je, filtrovat, kombinovat a postupně zpřesňovat dotazy podle potřeby. Výsledky lze ukládat, znovu spouštět a využívat jako podklad pro další práci.
Typickým příkladem z praxe byla práce se sbírkou Karla Absolona. Bylo potřeba zjistit, která díla nejsou digitalizovaná, ověřit jejich identifikátory a připravit podklady pro další práci.

Dříve by takový úkol znamenal několik hodin ruční práce. S Anakonem stačí nastavit kombinaci podmínek a během několika minut získáte rovnou použitelný přehled.
Rozdíl však není jen v rychlosti. Důležitější je, že výsledek nekončí u jedné tabulky, ale otevírá prostor pro další otázky a analýzu.

V knihovnách často existují dva paralelní světy: katalog a digitální knihovna. Každý z nich pracuje s daty trochu jinak a jejich propojení není automatické.
Digitální knihovna často odráží stav katalogu v okamžiku digitalizace. Jakmile se katalogový záznam později upraví, změna se nemusí do digitální knihovny propsat. Postupně tak vzniká nesoulad mezi tím, co katalog obsahuje, a tím, co je dostupné v digitální knihovně.
Bez vhodného nástroje je přitom systematické odhalování nesrovnalostí velmi obtížné. Kontrola probíhá spíše jednotlivě a nárazově, podle konkrétní potřeby.
Anakon umožňuje tento nesoulad hledat cíleně – ne po jednotlivých případech, ale napříč celým fondem a ve větším měřítku.
Frustrace při práci s daty často nevzniká kvůli jejich složitosti. Vzniká ve chvíli, kdy člověk ví, co potřebuje zjistit, ale nemá nástroj, jak to udělat.
Anakon tuto bariéru snižuje. Umožňuje pracovat s daty samostatně, zkoušet různé dotazy, ověřovat hypotézy a reagovat okamžitě. Knihovník nečeká na volnou kapacitu IT oddělení, ale hledá odpovědi přímo při práci.
Typickým příkladem jsou tzv. dlouhotrvající dotazy pro práci s většími objemy dat nebo s informacemi běžně nedostupnými v indexu. Takové dotazy obvykle připravuje technický pracovník, protože jejich sestavení vyžaduje znalost struktury dat.

Tím se mění charakter práce. Z mechanického sběru dat se stává jejich interpretace a analýza. Zároveň se uvolňuje napětí mezi odborníkem a IT – oba se mohou soustředit na práci, která jim dává větší smysl.
Práce s daty je tak nejen dlouhodobě méně vyčerpávající, ale především udržitelná.
Anakon vyvíjí Trinera jako open source řešení ve spolupráci s Moravskou zemskou knihovnou. Je navržen tak, aby mohl pracovat se standardizovanými daty a přizpůsobit se různým prostředím.
Nevznikl jako univerzální nástroj pro všechno, ale jako odpověď na konkrétní problém: jak pracovat s daty systematicky, bez zbytečných bariér a závislostí.
Anakon tak představuje otevřený základ pro systematickou práci s daty, který má uplatnění všude tam, kde je potřeba hledat řád v rozsáhlých fondech – a to zdaleka nejen v knihovnách.
Pokud vás zajímá, jak může Anakon pomoci i vaší instituci – s kontrolou dat, analýzou, plánováním digitalizace nebo diagnostikou digitální knihovny – rádi se s vámi pobavíme.
👉 Kontaktujte Honzu Rychtáře, CEO Trinera
jan.rychtar@trinera.cz





