
.png)
.png)
ENG


V předchozích článcích jsme ukázali, jak tento nástroj dokáže překonat limity tradičního fulltextového vyhledávání a efektivněji zpřístupnit informace z digitálních knihoven. V tomto článku se na nástroj podíváme z odbornější perspektivy: jak jsme vybírali data, jaké technické a obsahové limity jsme překonali a jaké výzvy sémantické vyhledávání přináší. To totiž otevírá nové možnosti, ale zároveň klade vyšší nároky na kvalitu dat, jazykovou analýzu i způsob práce s výsledky.

Paměť novin je prototyp nástroje pro sémantické vyhledávání nad historickými texty, který jsme nedávno zpřístupnili k testování.
Sémantické vyhledávání porozumí významu dotazu, vyrovná se s nepřesnostmi v OCR nebo archaickým jazykem a zrychluje tak proces rešerší.
Z pohledu běžného uživatele představuje Paměť novin revoluční způsob, jak prohledávat historická periodika – stačí položit otázku v přirozeném jazyce, bez nutnosti znát dobovou terminologii nebo přesnou podobu výrazů. Při podrobnějším pohledu z odborné perspektivy se ale otevírá řada zajímavých souvislostí, rozhodnutí a výzev, které provázely samotný vznik tohoto nástroje.
Aby bylo sémantické vyhledávání skutečně užitečné, bylo nutné pečlivě vybrat vhodný datový korpus.
Při jeho budování jsme usilovali o co nejvyšší úroveň konzistence a spolehlivosti výsledků vyhledávání. Uvědomovali jsme si náročnost práce s historickými dokumenty, a proto jsme se zaměřili na pečlivý výběr zdrojů s vysokou historickou a výzkumnou hodnotou. Digitalizované noviny se ukázaly jako ideální volba, protože:
Důraz jsme kladli na obsahovou rozmanitost – do výběru jsme zahrnuli nejen celostátní deníky a týdeníky, ale také regionální tisk a tematická periodika zaměřená na různé společenské vrstvy. Tento přístup nám umožnil vytvořit nástroj s širokým záběrem, který nabízí hlubší porozumění dobovému kontextu.
Ačkoliv zatím pracujeme pouze se vzorkem dat, dbali jsme na to, aby reprezentoval různé typy periodik a poskytl co nejkomplexnější obraz tehdejšího společenského dění. Pro účely vývoje prototypu jsme zpracovali 500 tisíc stran (65 tisíc výtisků) z 25 českých periodik vydaných v letech 1880–1914. Tyto tituly jsou volně dostupné v pěti různých digitálních knihovnách používajících systém Kramerius.
V našem případě klíčovou roli při výběru sehrála zejména ucelenost dat – tematická (noviny), časová (1880-1914) a místní (česky psané noviny z našeho území).
Pokud by byl obsah tematicky či typově nejednotný, například pokud by se mísily zpravodajské články s beletrií nebo vědecké texty s populárními články, vedlo by to ke zkresleným výsledkům a ztížilo by to orientaci uživatele. Podobné problémy by způsobilo zahrnutí dokumentů z historických období bez přímé časové návaznosti, nebo z geograficky příliš vzdálených oblastí bez jasného vymezení.
Představme si, že bychom do jednoho souboru spojili například historické novinové články s knihou Válka s Mloky od Karla Čapka. Systém by pak mohl vrátit zprávy o reálných geopolitických událostech společně s fiktivními líčeními vzestupu inteligentních mloků, což by vedlo ke zmatku a chybným interpretacím.
Ačkoli jsme při výběru dat pro Paměť novin eliminovali zásadní problémy způsobené nesourodým obsahem – práce s jazykovými modely přináší nové typy problémů, se kterými je nutné při práci počítat.
Ani tematicky i časově ucelený datový soubor nezaručuje, že jazykový model vždy vyhodnotí kontext přesně. Zejména v případech příliš obecně formulovaných dotazů, nedostatku jednoznačně relevantních dokumentů, či nejednoznačných klíčových pojmů může model při generování odpovědi spojit dohromady texty, které spolu významově souvisejí jen volně, nebo vůbec. Taková odpověď pak může působit přesvědčivě, ale při bližším pohledu je nepřesná nebo zavádějící.
Například situace v Evropě v roce 1898 byla napjatá – velmoci soupeřily o vliv v koloniích, docházelo k vojenskému posilování a rostlo napětí na Balkáně. Tato atmosféra by teoreticky mohla zpětně připomínat i události roku 1914, kdy vypukla první světová válka. Pokud by však algoritmus pracoval s texty z těchto dvou období bez vědomí časové souvislosti, mohl by při položení obecnějších otázek vytvořit mylný dojem, že diplomatická roztržka z roku 1898 byla přímou příčinou války v roce 1914.
Podobně by mohlo být zavádějící spojovat novinové články z různých regionů, například z velkých měst a venkovských oblastí, aniž by byly zohledněny místní rozdíly v mentalitě, jazyce či socioekonomických podmínkách. Tato nejednotnost by mohla vést k nepřesnému obrazu tehdejší společnosti. Z tohoto důvodu jsme prozatím do aktuálního setu dat nezahrnuli tzv. krajanská periodika Čechů žijících v zahraničí, která hojně vycházela zejména v USA.
I když v naší aplikaci nejsou data smíšená náhodně a byla vybrána pečlivě, nelze zcela vyloučit, že v určitých případech nemůže dojít nesprávnému propojení informací, zejména u dotazů, které nejsou dostatečně konkrétní. Vždy je proto třeba odpovědi kriticky hodnotit a sledovat, z jakých zdrojových článků vycházejí.
Při výběru dat jsme čelili technickým omezením. Klíčové bylo, aby dokumenty obsahovaly textovou vrstvu ve formátu ALTO a zároveň podporovaly IIIF protokol. Bez těchto prvků by nebylo možné data správně zpracovat ani je nabídnout uživatelům.
Z tohoto důvodu jsme museli hned na začátku vyřadit některé významné tituly, například Národní listy, které by jinak představovaly velmi cenný historický zdroj. Ačkoli jsou tyto noviny digitalizované, chybí jim kvalitní a strukturovaný přepis textu, tedy je nelze analyzovat, rozčlenit do logických celků ani integrovat do systému.
Aby bylo možné efektivně využít sémantické vyhledávání, bylo potřeba rozdělit každou stránku na menší části, které spolu významově souvisejí.
Pokud bychom ponechali stránku jako jeden souvislý text, výstupy by byly příliš obecné, protože jednotlivé články mohou pokrývat různá témata. Systém by tak nedokázal určit, co přesně odpovídá položenému dotazu. Na druhou stranu, pokud bychom text dělili příliš podrobně, například po jednotlivých větách, ztratil by se kontext a odpovědi by působily roztříštěně.
Hledali jsme proto vyvážený přístup, který by umožnil zachovat smysl i čitelnost. Pomocí strukturálních informací obsažených ve formátu ALTO jsme rozdělili text na logické bloky o velikosti přibližně 500 až 1000 znaků.
Při tomto procesu jsme kombinovali různá pravidla – identifikovali jsme začátky článků podle typu písma a odsazení, rozeznávali odstavce a konce sloupců a pracovali s uzavřeností textových bloků. Výsledné části odpovídají jednotlivým článkům nebo jejich segmentům.

Výsledkem bylo v průměru 21 částí na jednu novinovou stránku. Při celkovém rozsahu zpracovaných dat to znamená více než 10 milionů samostatně indexovaných textových úseků. Každá z těchto částí obsahuje základní sadu metadat:
Díky tomu je možné propojit nalezené texty s původními zdroji, filtrovat přes datum a titul periodika, ale také zobrazit nalezený úsek přímo v digitální knihovně, kde se článek přiblíží a zvýrazní se.
Takto připravená data tvoří základ, na kterém může sémantické vyhledávání v Paměti novin fungovat efektivně. Umožňují systému lépe porozumět významu dotazu, zachovat kontext a současně nabídnout přesné a lokalizovatelné výsledky.
Během testování nástroje Paměť novin jsme narazili na několik témat, která si zaslouží hlubší zamyšlení. Práce s různorodými daty a širokou škálou uživatelských dotazů – napříč jazyky, žánry i regiony – ukázala, že i u pokročilých technologií existují limity a prostor pro další vývoj.
Jednou z klíčových výzev je práce s vícejazyčnými dotazy. Systém podporuje různé jazyky, což je významná výhoda, protože uživatelé nejsou omezeni pouze na češtinu. Zároveň však tato flexibilita přináší určité důsledky. Výsledky se mohou mírně lišit v závislosti na tom, jak je dotaz formulován.
Například:
Je důležité upozornit, že v obou případech se vyhledávalo ve stejném souboru českých periodik psaných česky. Rozdíl není v obsahu dat, ale ve způsobu, jakým jazykový model chápe a kontextualizuje dotaz. Vícejazyčnost tedy není pouze otázkou překladu, ale i kulturního rámce, v němž je otázka položena.
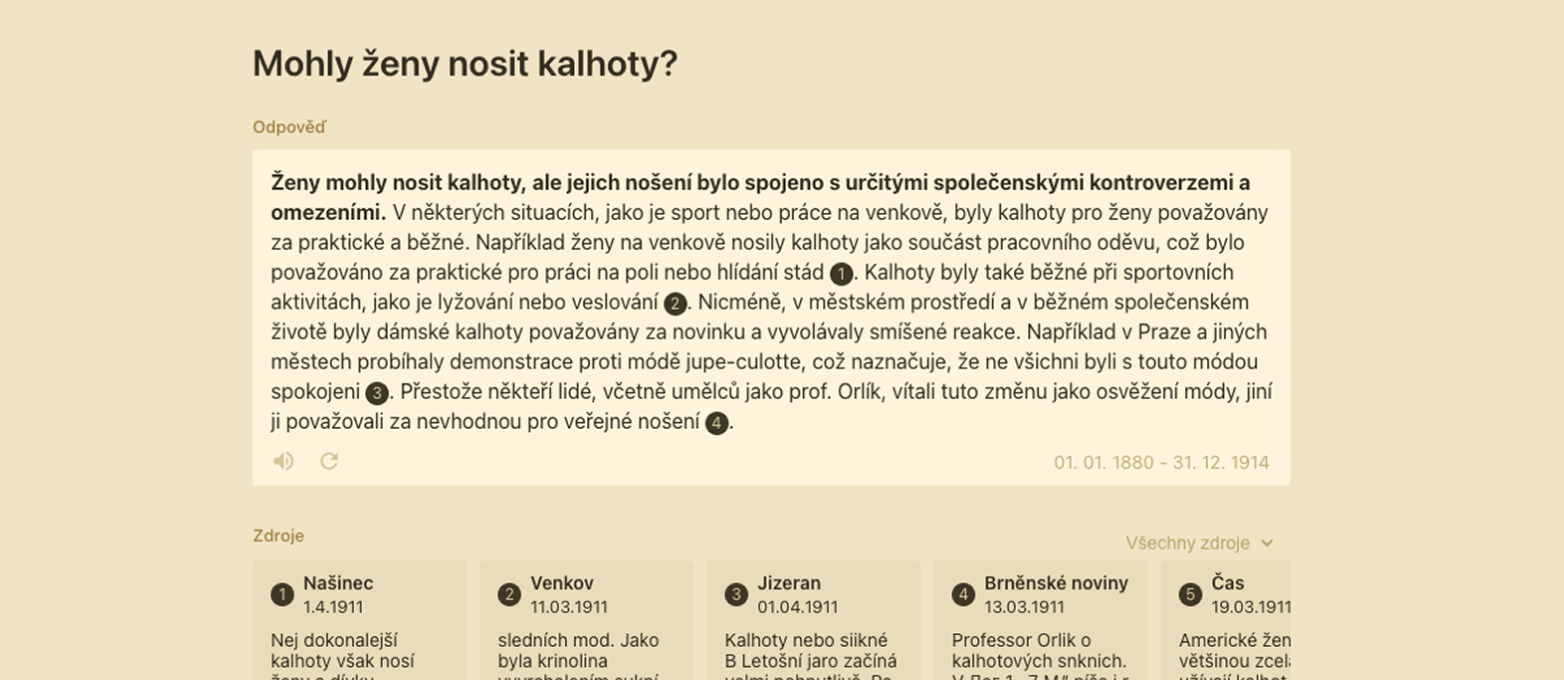

Dalším pozorováním je vliv míry konkrétnosti dotazu na výstup. Systém je velmi citlivý na formulaci – čím obecněji je dotaz položen, tím obecnější odpověď nabídne. Uživatel si ale může zvolit, zda chce hledat napříč všemi tituly, v určitém časovém intervalu nebo jen v jednom konkrétním periodiku. Tato volba výrazně ovlivňuje výsledky.
Například dotaz „Stěžovali si lidé na mládež?“ vrací při obecné volbě datasetu odpovědi shrnující články z různých období a regionů s občasným konkrétním příkladem, často popisující morální úpadek, hlučnost nebo nevychovanost mladých. Pokud však použijeme filtr na periodikum Plzeňský obzor, výstupy se zpřesní – zobrazí se články, které konkrétně popisují například konkrétní konflikty mladistvých s autoritami nebo alkoholismus a špatný vliv novin.
Možnost takto ovlivnit rozsah odpovědi je výhodou, ale zároveň klade důraz na správnou formulaci dotazu a porozumění principům, na kterých systém funguje.


Předpokládali jsme, že sémantické vyhledávání bude pracovat primárně s významem bez ohledu na jazyk textu. Testování však ukázalo, že jazyk dotazu i jazyk zdrojového dokumentu mají na výsledky zásadní vliv.
Pokud uživatel hledal informace v německých periodikách, musel dotaz formulovat německy – zejména u místních reálií. Například dotaz na situaci německých obchodníků v Brně kolem roku 1910 musel obsahovat označení Brünn, nikoli Brno. Systém v tomto případě nejspíš rozpoznal, že se jedná o stejné město, články z německých novin však do odpovědi nezařadil, jelikož jim přiřadil menší relevanci. A uživatel pak takové články ve výběru zdrojů nemohl najít.
Tento jev ukazuje, že jazykové nuance, zvláště u vlastních jmen a geografických názvů, stále hrají významnou roli. Do budoucna bude nutné tuto citlivost řešit například pomocí vícejazyčných map názvů nebo inteligentních přepisů dotazů.
Další výzvu představují specifické žánry obsažené v historickém tisku – například fejetony, romány na pokračování nebo reklamy. Tyto texty se často opakují, mají výrazný styl a někdy zabírají značnou část stránky. V důsledku toho mohou „přebít“ informačně hodnotnější články.
Typickým příkladem je dotaz na nejoblíbenější výrobek, např. jaké pivo bylo nejoblíbenější. Odpověď může být ovlivněna tím, které značky měly v dané době rozpočet na rozsáhlejší inzerci. Výsledky tedy neodrážejí reálné preference obyvatel, ale spíše movitost pivovaru a z toho vyplývající marketingový prostor v tisku.
Z toho důvodu bude do budoucna potřeba zvážit, zda tyto typy textů v určitých případech vylučovat, nebo je alespoň samostatně označit, aby při analýze nepůsobily rušivě.

Paměť novin je zatím pouze prototypem, který demonstruje možnosti sémantického vyhledávání v historických dokumentech. Obsahuje omezený vzorek dat, konkrétně 25 titulů českých periodik z let 1880 až 1914. Některé z těchto titulů navíc nejsou dochovány v úplnosti. U některých chybějí ročníky, které zatím nebyly digitalizovány, u jiných došlo v určitých obdobích k přerušení nebo ukončení vydávání.
Technicky vzato je možné podobný nástroj vytvořit i nad jinými soubory dat, ovšem historické noviny se ukázaly jako mimořádně vhodné médium, se kterým podle našeho názoru stojí za to pracovat i nadále.
V budoucnu lze očekávat, že digitální knihovny budou průběžně doplňovat nová data a zlepšovat kvalitu těch stávajících. Nepůjde jen o přesnější OCR přepisy, ale také o doplňování textové vrstvy ve formátu ALTO a zpřístupňování obrázků scanů přes IIIF protokol k dalším cenným zdrojům. Díky tomu bude možné dosáhnout ještě přesnějších výsledků vyhledávání a bude možné nabídnout širší přístup k digitalizovaným archivům.
Zajímá nás také, jak by se sémantické vyhledávání dalo využít i v jiných oblastech. Co kdyby např. nástroj jako Paměť novin zahrnoval kompletní korpus české novinové produkce – od počátku 19. století až po konec 20. století? Takový rozsah by otevřel nové možnosti výzkumu, a to sledování proměn společenského diskurzu, vývoje jazyka i proměny stereotypů v průběhu času.
Díky tomu by bylo možné studovat, jak se historická paměť utváří, jak se opakují určité narativy nebo jak tisk reagoval na klíčové momenty moderních dějin.
Taková vize je zatím v dálce, ale technologie jako Paměť novin k ní mohou postupně připravit cestu. Aby se stala realitou, bude potřeba řešit řadu dalších aspektů – nejen technických, ale i právních. Zejména otázka autorských práv u části novinové produkce bude hrát zásadní roli a vyžádá si systematické řešení. Cesty existují, ale vyžadují širší mezioborovou diskusi, která přesahuje rámec tohoto textu.
Do dalších fází vývoje chceme zahrnout i personalizaci uživatelského prostředí, zohlednění preferencí jednotlivých uživatelů a možnost kombinovat různé typy dotazů. Naším cílem je, aby se Paměť novin nestala pouze výzkumným nástrojem, ale i spolehlivým každodenním pomocníkem – pro badatele, vyučující, studenty i širokou veřejnost.

Paměť novin není jen nástrojem pro vyhledávání v historických textech, ale také prostorem pro další výzkum a experimentování. Testování ukázalo, že i přes pokročilou technologii stále existují výzvy – od práce s vícejazyčnými zdroji přes správnou interpretaci dotazů až po žánrové odlišnosti historických textů. Stojíme proto před otázkami, jak výsledky lépe přizpůsobit potřebám badatelů, jak zefektivnit analýzu dat a jaké nové technologie mohou pomoci posunout možnosti vyhledávání ještě dál.
Do budoucna plánujeme:
Budeme rádi, pokud se s námi podělíte o své zkušenosti – co vám fungovalo, co vám chybělo a co by vám pomohlo při každodenní práci s historickými dokumenty.
👉 Pokud si chcete ověřit, jak tato technologie funguje v praxi, vyzkoušejte Paměť novin na www.pametnovin.cz. Nově můžete Paměť novin sledovat i na sociálních sítích, konkrétně na Facebooku a Instagramu.
👉 Chcete podobné vyhledávání i ve vaší instituci a nad vlastními daty? Ozvěte se nám a rádi s vámi možnosti nezávazně probereme.





