
.png)
.png)
ENG


A system designed for faster and more accurate creation of bibliographic records with the help of artificial intelligence. This is not a black box that generates MARC21 records unchecked, but a thoughtful chain of precisely defined steps, algorithms and specialized models that serves as a clever co-pilot of the cataloger.
Many institutions manage vast pools of previously uncatalogued documents. Manual cataloging of such a volume of data would take decades at current capacities, leaving many documents unavailable to researchers and the public alike.
When cataloging, it is necessary to read bibliographic data from documents, verify their correctness, trace authorities, compare existing entries in catalogs and only then compile the resulting bibliographic record.

Much of this work is repetitive and time-consuming:
As a result, the professional capacity of the catalogers is not sufficient for the scope of the funds and a large part of the documents remains undescribed for a long time and thus practically invisible.
This is where AI can help significantly. It does not replace the work of a specialist, but takes over routine steps, saves time and provides the cataloger with quality materials for his activities.
The basis of the system is a transparent workflow, in which each model and algorithm has a clearly defined role and everything is subject to human control.
The process typically works like this:

An important principle is that LLM does not generate a final bibliographic record as a whole. Critical data, such as author identifiers, dates of birth and death, or authoritative forms of names, are taken from trusted databases. In the same way, all existing records are searched in local, comprehensive and foreign catalogues and can be taken over in whole or in part.
The result is a system that combines the power of AI with the precision of cataloging practice.
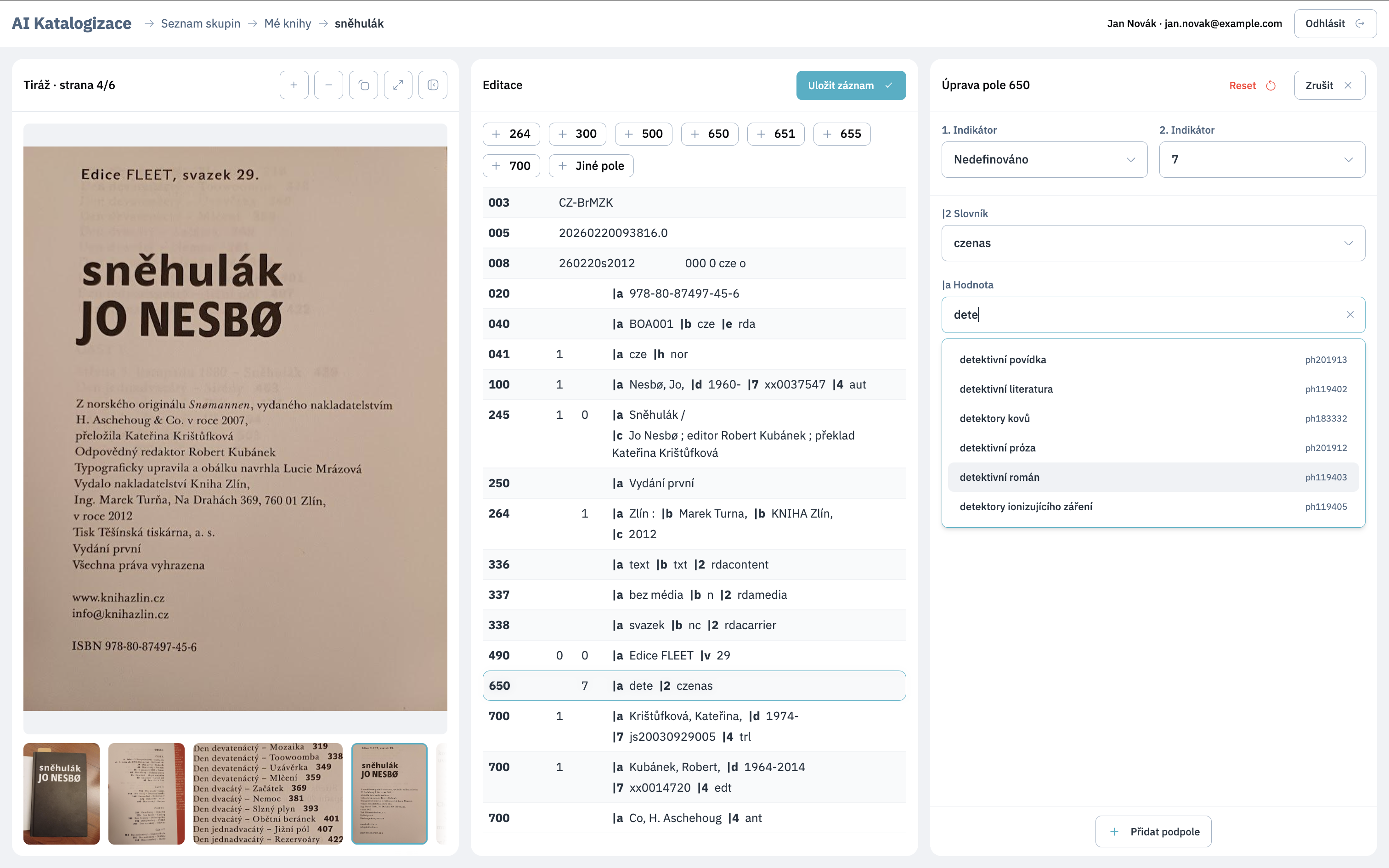
Part of the application is also full-featured web MARC21 editorthat meets current usability and flexibility requirements.
The editor offers:
Thus, the cataloger does not work with an isolated AI tool, but with a comprehensive environment in which the record design can be conveniently reviewed, supplemented and finalized.
The implementation of the system brings several fundamental advantages:
The system helps catalogers focus on expert assessment of the record instead of mechanically rewriting and tracing.
The architecture of the system is designed in a modular way, which allows it to be further expanded according to the needs of a particular institution as well as the development of cataloging standards.
In the future, there are a number of directions in which solutions can be further developed:
It is the last scenario that opens up new possibilities for working with data. If a digitized document is available in its entirety, the system can work with the contents of the entire publication, identify topics, extract structure, or supplement metadata that was previously unavailable.
Thanks to this, the system can gradually move from supporting the cataloging of individual documents to complex processing and enrichment of library funds.

At the same time, the solution also creates room for the future transition from MARC towards BIBFRAMEwithout the need to fundamentally change the approach to data processing.
The whole project shows that AI can be a practical and trustworthy assistant in cataloging when used judiciously, transparently and in combination with expert control.
The principle on which the system is built is not limited to library cataloging alone. The same approach — a combination of data extraction, standardization, validation against reference sources, and controlled result compositing — can be used wherever organizations are working with documents and need to create structured data from them.
Typical examples may be:
In these scenarios, a similar problem often arises as in libraries: professional staff spend a large amount of time on routine tasks that can be automated, but at the same time it is necessary to maintain control over the quality of the data.
The solution is a system that does not work as a black box, but as transparent AI assistantthat combines automation with human decision making.





