
.png)
.png)
ENG


Library data are vast, vibrant and constantly changing. They migrate, replenish, repair. They often arise for decades and carry historical layers of older rules, retroconversions, and manual interventions. And when one begins to systematically review an institution through a catalog or digital library, one quickly discovers that one patch reveals other problems.
.png)

Na AKM conference 2025 We likened this phenomenon to fighting a hydra — you chop off one head and grow three more.
This is not just about libraries. Any organization that works with a large amount of data has a similar experience. As data grows and evolves over time, inconsistencies, duplications, or non-uniform notations naturally begin to appear in it.
Experts often know that something is wrong with the data. It sees individual errors, but does not have a tool that allows it to simply find out their scope or connections on a larger scale.but it cannot
And that's why Anacon was created.
A number of activities when working with data seem simple at first glance. I need to prepare handouts, check data consistency, verify links between systems, or create an overview for further decision-making.
But in practice, these tasks often break down into dozens of small steps:
Such work is time-consuming and difficult to scale. The larger the volume of data, the less realistic it is to do it manually. At the same time, the pressure for accuracy is growing.
The result is a paradox: people with deep knowledge of data spend much of their time doing mechanical activity instead of actually analyzing the data. And since the data is constantly changing, the result of such work quickly becomes obsolete and needs to be repeated.
In many institutions, it handles data analysis through the requirements of IT departments. Librarian needs data, technician prepares query and export. This model on paper works, but in practice it has its limits.
The librarian formulates the request, IT implements it and returns the result after time. But it turns out that the assignment needed to be refined. The next iteration follows. In the meantime, the data will change or new questions will appear.
The process is repeated.

Another barrier is communication language: everyone works with data in a different way and thinks about it differently. The librarian handles the contents and structures of the record, the technical worker handles databases and indexes. The result is then tuned sequentially, sometimes several iterations.
This endless cycle is in no way unusual or exceptional even outside the library environment. It arises wherever analytical needs are separate from the tools that work with the data, and leads to long-term frustration on both sides.
Anakon's roots go back to 2012. At the time, Honza Rychtář (CEO of Trinera), as a programmer at the Moravian Library, constantly dealt with the requirements for extracts and data checks that the catalogue could not offer. Instead of repeatedly writing scripts, he created MarcScanner - an internal tool that allowed librarians to work with data in an advanced way without the assistance of an IT department.
It wasn't a product or a systemic change. More like a practical response to a specific need.
Later it became apparent that the same principle has wider application — especially when it is necessary to work not only with the catalog, but also with the digital library and their interconnections. As part of the project of the National Renewal Plan, Anakon was created for the needs of the Moravian Regional Library.
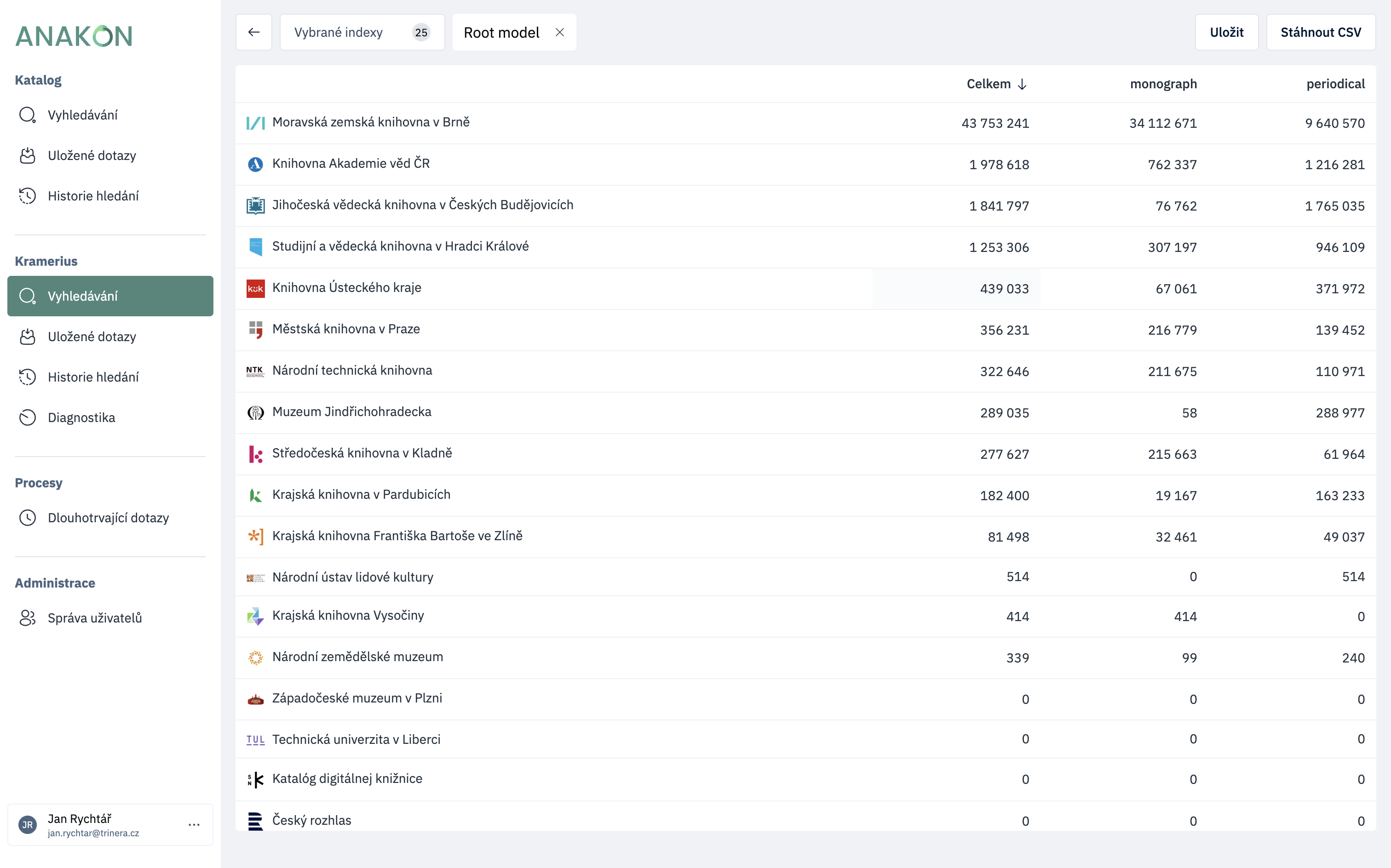
Anacon is an analytical and control tool that complements existing systems. It does not replace a catalog or digital library and does not serve to edit data directly. But beyond data, it allows you to ask questions for which conventional interfaces are not enough.
The user selects the data source, sets the conditions and gets the result in the form of a clear table. Each row corresponds to one record, the individual columns represent the selected data or control values.
This way of working is important. It's not just about finding data, it's about seeing it in context — sorting, filtering, combining and refining queries as needed. The results can be saved, restarted and used as a basis for further work.

A typical example from practice was the work with the collection of Karl Absolon. It was necessary to find out which works are not digitized, to verify their identifiers and to prepare documents for further work.
Previously, such a task would entail several hours of manual labor. With Anacon, you just need to set a combination of conditions and you will get a straight usable overview within minutes.
But the difference is not only in speed. More importantly, the result does not end at one table, but opens up space for further questions and analysis.
There are often two parallel worlds in libraries: the catalog and the digital library. Each of them works with data a little differently, and linking them is not automatic.
A digital library often reflects the status of a catalog at the time of digitization. Once the catalog record is modified later, the change does not have to be written into the digital library. Gradually, there is a discrepancy between what the catalog contains and what is available in the digital library.
Without a suitable tool, systematic detection of irregularities is very difficult. The inspection takes place rather individually and bumpy, according to the specific need.
Anakon makes it possible to search for this discrepancy in a targeted manner — not on a case-by-case basis, but across the entire fund and on a larger scale.
Frustration when working with data often does not arise because of its complexity. It arises at the moment when a person knows what he needs to find out, but does not have the tool to do it.
Anacon lowers this barrier. It allows you to work with data independently, try different questions, verify hypotheses and respond instantly. The librarian does not wait for the spare capacity of the IT department, but looks for answers directly at work.

This changes the nature of the work. Mechanical data collection becomes their interpretation and analysis. At the same time, the tension between the professional and the IT is easing -- both can focus on work that makes more sense to them.
Working with data is thus not only less exhausting in the long term, but above all sustainable.
Anakon is developing Triner as an open source solution in cooperation with the Moravian Library. It is designed to be able to work with standardized data and adapt to different environments.
It arose not as a universal tool for everything, but as an answer to a specific problem: how to work with data systematically, without unnecessary barriers and dependencies.
Anakon thus represents an open basis for systematic work with data, which can be used wherever there is a need to find order in large funds — and not only in libraries.
If you're wondering how Anakon can help your institution — with data control, analysis, digitization planning or digital library diagnostics — we'd love to talk to you.
👉 Contact Honza Rychtář, CEO of Triner
jan.rychtar@trinera.cz





